Qwen3-235B schlägt Claude beim Coding. Kimi K2.5 läuft in Cursor Composer 2. Was Open-Source-Modelle auf Ollama Pro wirklich können – und wann sie sich lohnen.
Cursor Composer 2 läuft auf einem Open-Source-Modell. Kimi K2.5, entwickelt von Moonshot AI. Das hat mich überrascht. Ich hatte erwartet, dass Cursor auf Claude oder GPT-5 setzt, wie alle anderen.
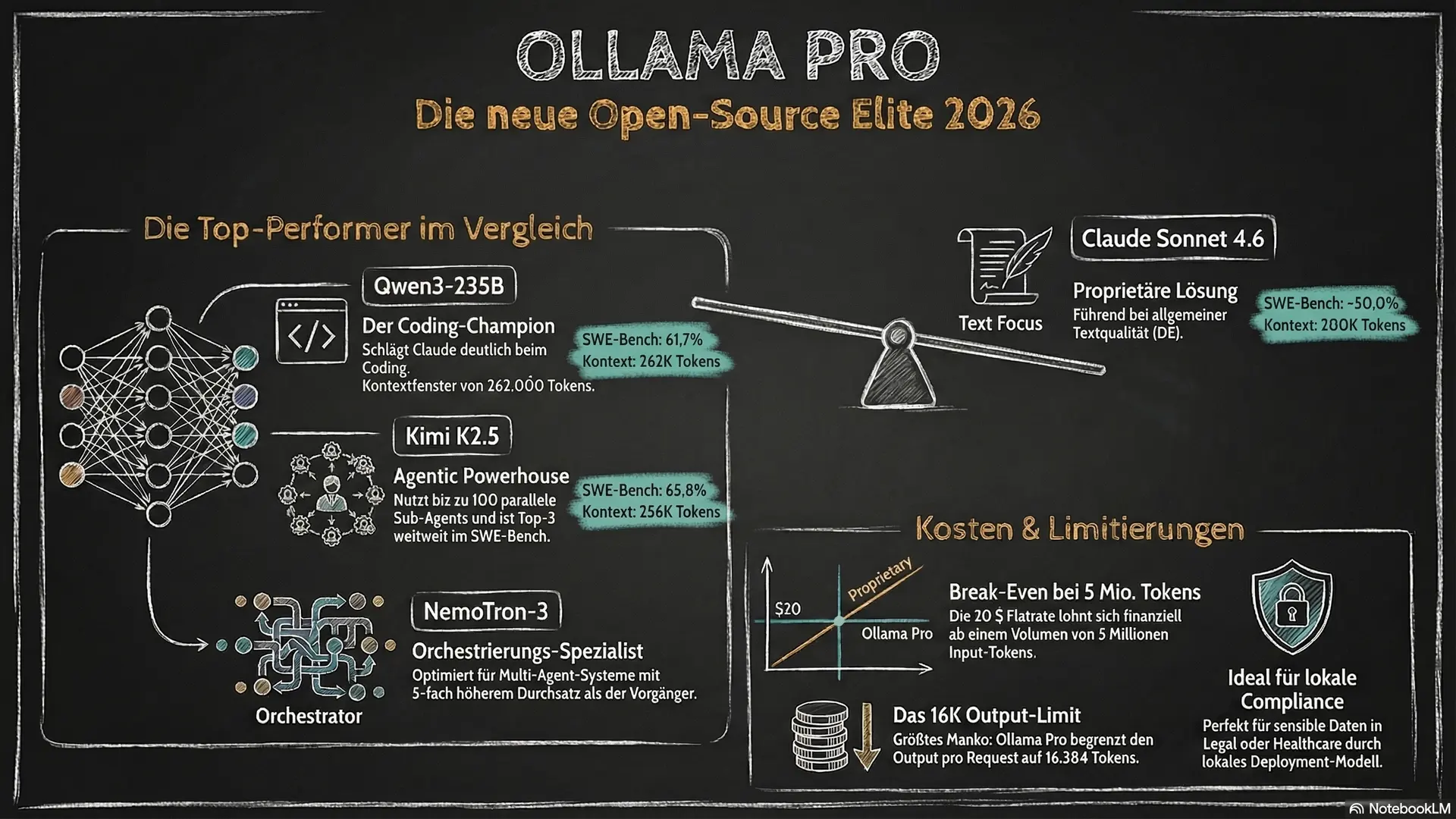
Aber genau das ist der Punkt. Open-Source-Modelle sind 2026 keine experimentelle Alternative mehr. Qwen3-235B schlägt Claude beim Coding. Kimi K2.5 liegt mit 65,8% auf SWE-Bench unter den Top 3 weltweit. Und beides läuft auf Ollama Pro für pauschal $20 im Monat.
Was kannst du damit konkret machen? Wo sind die Limits? Und wann lohnt sich das gegenüber Claude oder GPT? Das klären wir jetzt.
Im großen KI-Subscription-Vergleich 2026 haben wir alle vier Abos gegenübergestellt. Dieser Artikel geht tiefer in Ollama Pro.
Das 16K-Limit: Was Ollama Pro dir nicht sagt
Erstmal das Wichtigste, das in keinem Review steht: Ollama Pro hat ein Output-Limit von 16.384 Tokens pro Request. Claude liegt bei 100.000+ Tokens Output. Das ist ein gravierender Unterschied.
Was bedeutet das praktisch? Ein langer Blogbeitrag (3.000 Wörter) liegt bei rund 4.000 Tokens. Ein mittleres Python-Skript mit 300 Zeilen: etwa 2.000 Tokens. Du kannst in einem Request grob fünf bis sechs Artikel auf einmal generieren lassen, oder acht bis zehn Codedateien. Für einzelne Tasks reicht das völlig. Für Codebasen mit Tausenden von Dateien brauchst du einen anderen Ansatz.
Session-Limits? Nicht öffentlich spezifiziert. Ollama rechnet nach GPU-Time, nicht nach Tokens. Wie viele Tokens du in 5 Stunden wirklich machen kannst: unklar. Das ist opaque und ein echtes Manko.
Die drei Modelle: Wer ist für was da
Qwen3-235B (Alibaba)
Das klingt nach Monster-Modell. Ist es auch, aber effizienter als du denkst. Die 235 Milliarden sind Gesamtparameter, aktiv sind nur 22B pro Token. Mixture-of-Experts-Architektur: 128 Experten, 8 werden pro Token aktiviert. Ergebnis: Geschwindigkeit eines 22B-Modells mit der Intelligenz eines 235B-Modells.
Kontextfenster: 262.000 Tokens. Mehr als Claude (200K), mehr als GPT-5.4 (128K).
Auf Deutsch läuft das problemlos. Multilingual ist eine der echten Stärken.
Kimi K2.5 (Moonshot AI)
Der Überraschungskandidat. Kimi war vor einem Jahr kaum bekannt. Jetzt läuft Cursor Composer 2 darauf.
Warum? Kimi K2.5 wurde explizit für agentic Tasks trainiert. Tool-Use, Web-Search-Integration, Multi-Step-Reasoning. Das spiegelt sich in SWE-Bench wider: 65,8% Verified, top 3 weltweit, proprietäre Modelle eingeschlossen.
Das Einzigartige: bis zu 100 Sub-Agents parallel. Claude ist Single-Agent. GPT auch. Kimi verteilt komplexe Aufgaben auf einen Schwarm und ist dadurch laut eigenem Benchmark 4,5x schneller bei der Execution. Kein Marketing-Bla, das steckt in Cursor Composer.
Kontextfenster: 256.000 Tokens.
NemoTron-3-Super (NVIDIA)
120B Parameter, 12B aktiv. Hybrid Mamba-Transformer. Nicht für Text oder Coding im klassischen Sinn, sondern für Multi-Agent Orchestration. PinchBench Agentic Reasoning: 85,6%. Höchste Punktzahl unter allen open-source Modellen in diesem Bereich. Throughput ist 5x höher als beim Vorgänger. Wer viele gleichzeitige Anfragen hat, ist hier gut aufgehoben.
Benchmarks: Wie gut ist das wirklich?
| Modell | CodeForces ELO | SWE-Bench Verified | MMLU-Pro | Context |
|---|---|---|---|---|
| Kimi K2.5 | ~1.900 | 65,8% | ~82% | 256K |
| Qwen3-235B | 2.056 | 61,7% | 84,4% | 262K |
| GPT-5.4 | ~2.200 | ~75% | ~92% | 128K |
| Claude Sonnet 4.6 | ~1.500 | ~50% | ~89% | 200K |
| Gemini 3.1 Pro | ~1.950 | ~58% | 89,2% | 1M |

Coding: Qwen3 gewinnt gegen Claude, deutlich. Agentic: Kimi gewinnt gegen Claude, auch deutlich. Auf MMLU-Pro (allgemeines Wissen, Reasoning) liegen beide hinter GPT und Claude.
Das Fazit: Für Coding und agentic Tasks sind die Open-Source-Modelle auf Ollama Pro konkurrenzfähig mit proprietären Anbietern. Für allgemeines Schreiben auf Deutsch oder komplexes Reasoning liegt Claude noch vorne.
Die Kostenrechnung: Ab wann lohnt es sich?
Claude Sonnet 4.6 API: $3 pro Million Input-Tokens, $15 pro Million Output-Tokens.
| Szenario | Claude API | Ollama Pro | Gewinner |
|---|---|---|---|
| 1M Input + 500K Output/Monat | ~$10,50 | $20 | Claude API |
| 5M Input + 2M Output/Monat | ~$45 | $20 | Ollama Pro |
| 50M Input + 20M Output/Monat | ~$450 | $20 | Ollama Pro |
| 500M+ Token/Monat | ~$4.500 | $20 | Ollama Pro |
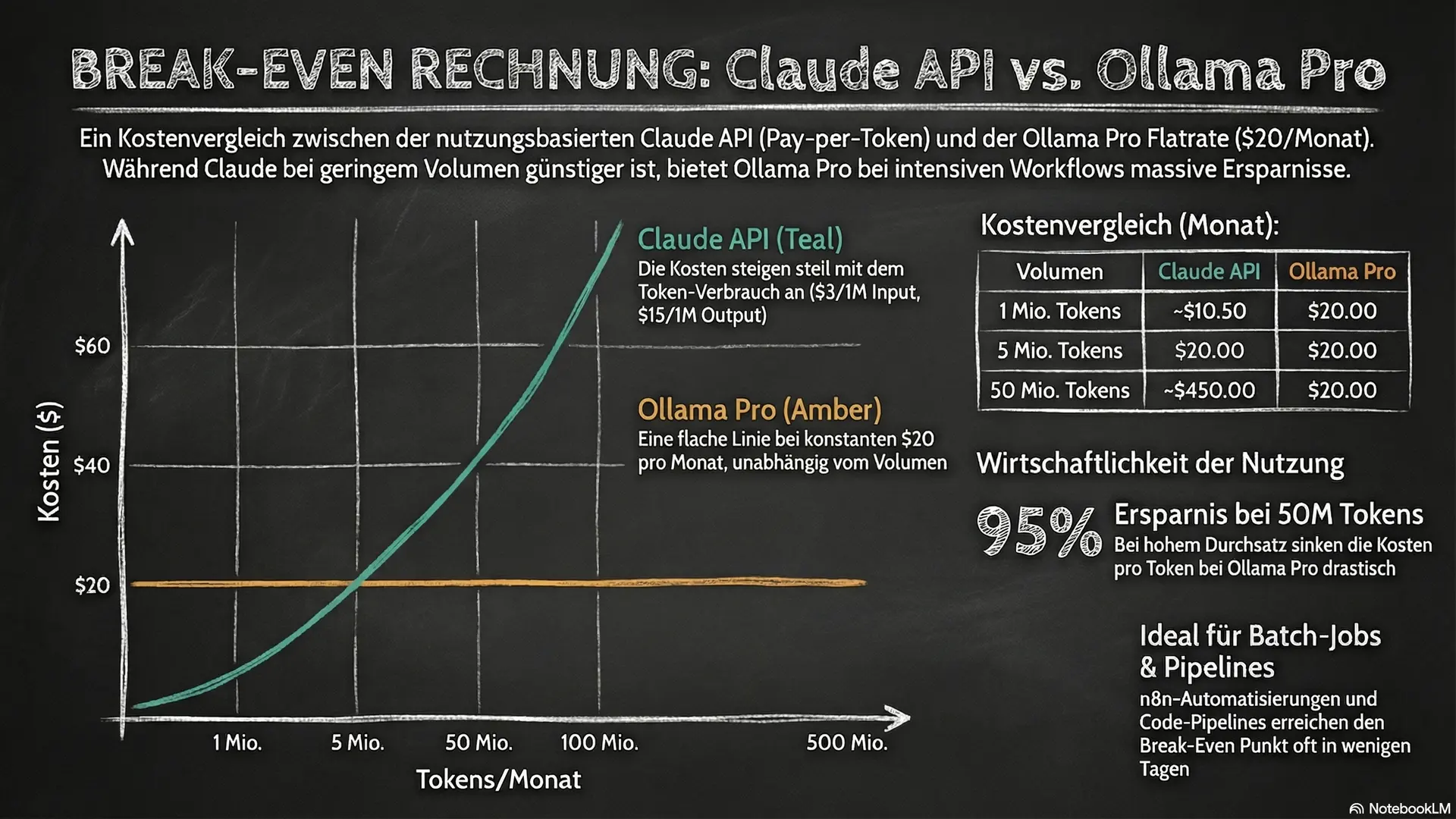
Break-Even liegt bei etwa 5 Millionen Input-Tokens pro Monat. Das klingt viel. Ist es aber nicht, wenn du Modelle in Workflows integrierst: n8n-Automatisierungen, Code-Generation-Pipelines, Batch-Jobs. Da knackst du 5M schnell.
Wenn du Claude als Chat-Tool nutzt statt als API: anderer Vergleich. Da zahlst du beide Male ~€20 pauschal, und Claude gewinnt dann auf Qualität für Text.
6 Use Cases wo Open-Source gewinnt
1. Agentic Coding-Workflows
Kimi K2.5 mit 100 Sub-Agents parallel macht Sachen, die Single-Agent-Claude schlicht nicht kann. CI/CD-Bots, die Code reviewen, Tests schreiben und Bugs fixen gleichzeitig. 4,5x schneller als alles andere in dieser Kategorie. Cursor Composer 2 ist der Beweis: das ist production-ready.
2. Competitive Programming und Algorithmen
Qwen3-235B hat CodeForces ELO 2.056. Das ist Grandmaster-Niveau. Für komplexe algorithmische Aufgaben, Mathe-Reasoning oder STEM-Probleme ist das die erste Wahl. Claude kommt hier nicht ran.
3. Long-Context Document Analysis
262K Tokens bei Qwen3, 256K bei Kimi. Beide mehr als Claude (200K). Wenn du komplette Bücher, umfangreiche Rechtsdokumente oder große Codebasen auf einmal analysieren willst, ohne in Chunks aufzuteilen: hier.
4. Datenschutz und Compliance
Kein Datenfluss zu externen Servern. Kein Training auf deinen Daten. EU AI Act compliant. Für Healthcare, Legal oder sensitive Business-Daten ist Local Deployment der einzig sichere Weg. Ollama macht das einfach.
5. API-intensive Automatisierungen
n8n-Workflows, Batch-Jobs, Nacht-Pipelines. Wenn du 50+ Anfragen pro Tag automatisiert abfeuerst, knackst du bei Claude API schnell das Budget. Ollama Pro ist Flatrate. Kein Token-Zählen, kein Budget-Monitoring.
6. Frontier-Modelle testen ohne Risiko
Du willst Qwen3-235B ausprobieren? Kimi K2.5 gegen Claude benchmarken? Auf Ollama Pro geht das ohne Angst vor der Rechnung. Kein Pay-per-Token. Einfach testen.
Wann Ollama Pro keine gute Idee ist
Das 16K Output-Limit ist ein echter Stopper für bestimmte Aufgaben. Sehr lange Texte in einem Request, massive Codefiles, komplette Bücher: Claude oder andere Lösungen sind besser geeignet.
Session-Limits sind intransparent. Du weißt nicht, wie viele Tokens du in 5 Stunden machen kannst. Das macht Planning schwierig.
Für deutschen Fließtext, Blogbeiträge, Newsletter: Claude bleibt besser. Die Sprachqualität auf Deutsch ist bei Claude immer noch höher als bei open-source Modellen. Kein klarer Ausreißer bei Ollama hier.
Mein Fazit
Ollama Pro ist kein Claude-Ersatz. Das will es auch nicht sein.
Aber für Coding, für agentic Tasks, für Datenschutz-Requirements und für API-heavy Workflows ist es 2026 eine ernsthafte Option. Qwen3-235B schlägt Claude beim Coding. Kimi K2.5 schlägt alles bei Multi-Agent-Tasks. Cursor nutzt es. Das sagt alles.
Ich werde es als Ergänzung testen. Für n8n-Pipelines und Batch-Jobs. Lokale Alternative hab ich mit Qwen3-14B eh schon auf der 5080, Ollama Pro wäre der Upgrade-Pfad wenn ich mal 200B-Modelle brauche ohne die GPU zu overloaden.
Ob sich die $20 lohnen, hängt komplett davon ab was du damit machst. Für reines Chat-Replacement: nein. Für automatisierte Workflows und Coding: ja.
Quellen & Links
- Qwen3 Technical Report (arXiv:2505.09388)
- Kimi K2.5 Tech Blog
- NVIDIA Nemotron 3 Super
- Ollama Cloud Pricing
- Anthropic Claude Pricing
- Artificial Analysis LLM Leaderboard
- TechCrunch: Cursor Composer 2 und Kimi K2.5
— TRMT