- Ollama (CLI), LM Studio (GUI) oder Jan.ai, kostenlos, DeepSeek V3, Llama 3.1, Mistral, Qwen, Gemma
- 8-12GB VRAM sweet spot, 7-8B Modelle 40+ Tokens/sec, schneller als Cloud-APIs
- Q4_K_M Quantization 75% weniger RAM, minimal schlechter, Dual-Strategie (lokal Standard, Cloud Complex)
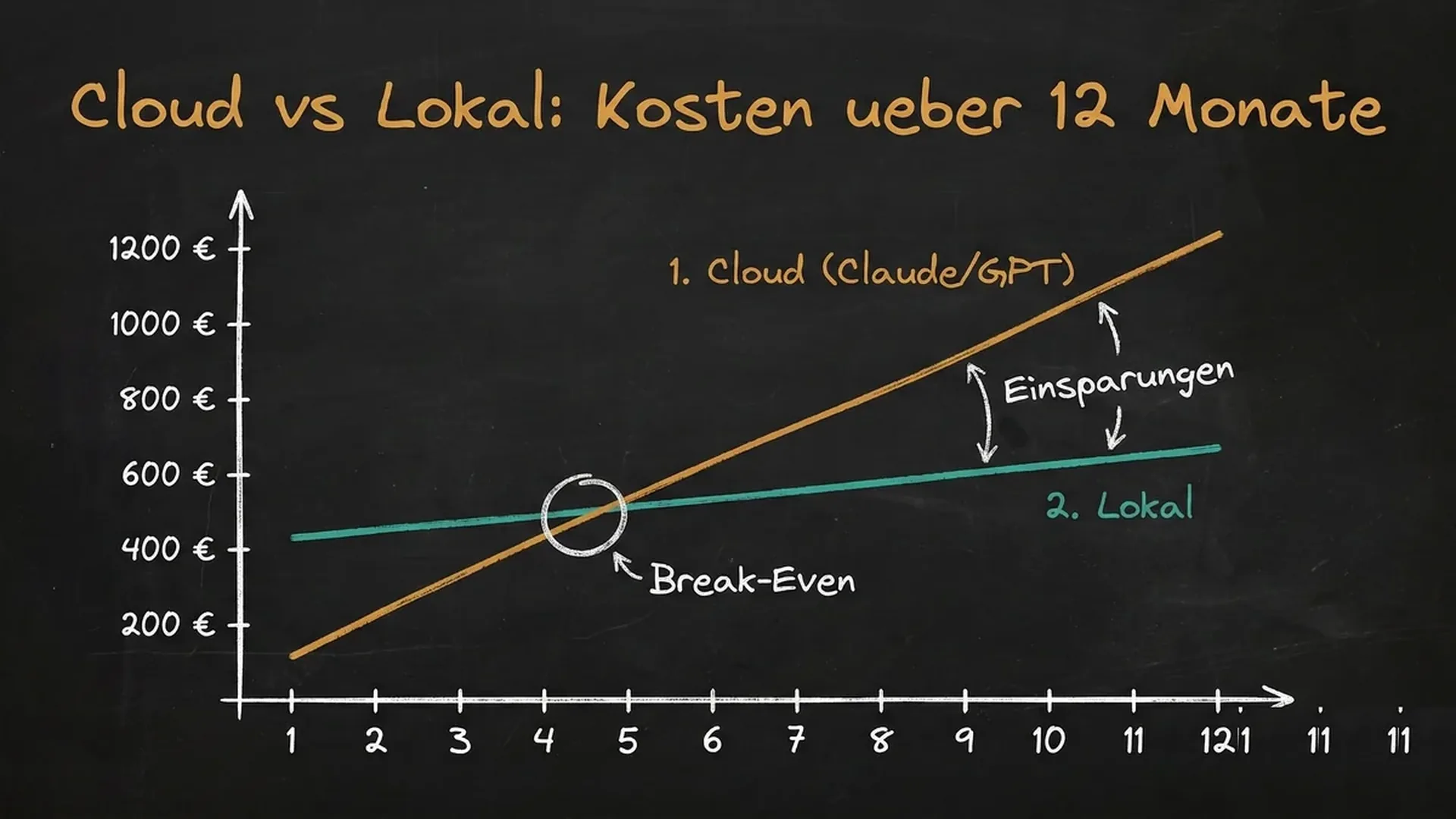
- Privacy, Zero Data Exfiltration, DSGVO-konform, Break-Even 2-6 Monate, dann praktisch gratis
Jeder Prompt, den du an ChatGPT schickst, landet auf einem Server in den USA. Jedes Code-Snippet, jeder private Text, jede Geschäftsidee.
Oder du lässt die KI auf deinem eigenen Rechner laufen. Lokal. Privat. Offline. Kostenlos nach dem Hardware-Investment.
2026 ist das erstmals wirklich praktisch.
Ollama vs LM Studio vs Jan.ai
| Ollama | LM Studio | Jan.ai | |
|---|---|---|---|
| Interface | CLI | Desktop-App | Desktop-App |
| Bedienung | Terminal-Befehle | Visuell, klickbar | Visuell, simpel |
| API | OpenAI-kompatibel | OpenAI + Anthropic | OpenAI-kompatibel |
| Modelle | 100+ in Library | Hugging Face Browser | Integrierter Hub |
| RAG | Über Open WebUI | Direkt im Chat | Nein |
| GPU Support | NVIDIA, AMD, Apple | NVIDIA, AMD, Apple | NVIDIA, Apple |
| Preis | Kostenlos | Kostenlos | Kostenlos |
| Best für | Entwickler, Scripting | Einsteiger, GUI-User | Privacy-Puristen |
Ollama für Entwickler (CLI + API + Scripting). LM Studio für alle, die eine hübsche GUI wollen. Jan.ai für Leute, die Open Source wichtig finden.
Meta Llama 3.x. Der Allrounder
Llama 3.1 in 8B, 70B und 405B Parametern. Das 8B-Modell läuft auf praktisch jedem Gaming-PC mit 6GB VRAM. 128K Context Window.
Bestes Allround-Modell für Coding, Writing, Reasoning. Quasi der “GPT-3.5 Killer” in Open Source.
DeepSeek V3.2. Der Game-Changer
685 Milliarden Parameter, 128K Context, MIT-Lizenz. Das Modell aus China, das die gesamte KI-Branche wachgerüttelt hat.
“Engram Conditional Memory” ermöglicht theoretisch 1M+ Token Context. V4 kommt bald.
Lokal: Braucht erhebliche Hardware (70B+ Quantized Version ist machbar mit 40GB VRAM).
Mistral Large 3. Der Europäer
41B aktive Parameter (675B total, Sparse MoE). Apache 2.0 Lizenz. Dezember 2025 Release.
Trainiert auf 3000 NVIDIA H200 GPUs. Top-Performance unter den frei verfügbaren Modellen.
Qwen 3.5. Der Preisbrecher
Von Alibaba. 0.5B bis 72B. Das 7B und 14B Modell sind der Sweet Spot für Consumer-Hardware.
Kostenlos, kommerziell nutzbar, GPT-3.5-Level. Für Coding und multilinguales Arbeiten stark.
Google Gemma 2. Der Kompakte
9B und 27B Parameter. Das 27B-Modell schlägt Modelle, die doppelt so groß sind.
Läuft sogar auf CPU (mit gemma.cpp). Perfekt für Systeme ohne dedizierte GPU.
Microsoft Phi-4. Der Spezialist
15B Parameter mit Reasoning-Focus. Stark in Mathe, Wissenschaft, Chart-Analyse.
MIT-Lizenz. Multimodal (Text + Bild).

Welche Hardware brauchst du?
VRAM ist King
| Modellgröße | VRAM nötig (Q4_K_M) | System RAM | Speed |
|---|---|---|---|
| 7-8B | 4-6 GB | 16 GB | 40-50 Tokens/Sek |
| 13B | 8-10 GB | 16 GB | 30-40 Tokens/Sek |
| 32-34B | 16-20 GB | 32 GB | 20-30 Tokens/Sek |
| 70B | 35-40 GB | 64 GB | 10-20 Tokens/Sek |
Sweet Spot 2026: 8-12 GB VRAM. Damit laufen 7-8B Modelle bei 40+ Tokens pro Sekunde. Das ist schneller als die meisten Cloud-APIs.
GPU-Empfehlungen
NVIDIA RTX 4090 (24 GB). Top für Single-GPU. Alle Modelle bis 34B in voller Qualität.
AMD RX 7900 XTX (24 GB). Günstiger als NVIDIA, ROCm-Support wird 2026 besser.
Apple Silicon M3 Pro/Max. Unified Memory Advantage. 36 GB+ reicht für 70B Modelle.
Der Quantization-Trick
Q4_K_M Quantization reduziert den VRAM-Bedarf um 75% bei minimalem Qualitätsverlust.
Beispiel: Llama 3.1 8B in FP16 = 16 GB RAM. Dasselbe Modell in Q4_K_M = 5-6 GB RAM. Kaum spürbar schlechter, aber 3x weniger Hardware nötig.
Lokal vs Cloud: Der echte Vergleich
Geschwindigkeit
Lokal: Konsistent 10-100ms Latenz. Kein Internet nötig, kein Server-Lag.
Cloud: 100-500ms plus Network-Jitter. Bei Peak-Zeiten langsamer.
Für Real-Time Anwendungen (Code-Completion, Chat) ist lokal schneller.
Qualität
Cloud (GPT-5, Claude Opus): Besser für komplexes Reasoning, lange Kontexte, nuancierte Aufgaben.
Lokal (DeepSeek V3, Llama 70B): Erreichen für viele Standard-Tasks vergleichbare Qualität.
Realität 2026: Dual-Strategie. Lokal für Standard-Tasks, Cloud für Maximum Quality.
Kosten
Cloud (10M Tokens/Monat Input, 5M Output):
Claude Opus: ~175$/Monat. GPT-5: ~100$/Monat.
Lokal (nach GPU-Investment):
Strom: 30-50€/Monat. Sonst nichts.
Break-Even: 2-6 Monate bei Heavy Usage. Danach ist lokal praktisch gratis.
Integration: So nutzt du lokale KI im Alltag
Coding: Continue.dev + Ollama
Continue.dev ist eine VSCode-Extension, die sich mit Ollama verbindet. Tab Completion + Chat mit lokalen Modellen. Dein Code bleibt auf deinem Rechner.
VS Code ← HTTP → Ollama (localhost:11434) → Llama/Qwen-CoderPerfekt für proprietären Code, den du nicht an Cloud-APIs schicken willst.
Chat: Open WebUI
Open WebUI gibt Ollama ein hübsches Web-Interface. Plus: eingebautes RAG (Retrieval-Augmented Generation). PDFs hochladen, Fragen stellen, Antworten aus deinen Dokumenten.
docker run -d --gpus all -p 3000:8080
ghcr.io/open-webui/open-webui:latestBrowser auf → localhost:3000 → fertig.
15+ Web-Search-Provider integriert. Voice/Video Calls. Modell-Management. Alles lokal.
Dokument-Analyse
PDFs, Research Papers, Code-Repos durchsuchen. Alles lokal, keine Cloud-Uploads.
Für vertrauliche Dokumente (Verträge, Finanzen, Patente) ist das der einzig sinnvolle Weg.
Privacy: Das Killer-Feature
Jeder Prompt an ChatGPT wird geloggt. Möglicherweise für Model-Training genutzt. Subject zu Terms-of-Service-Änderungen.
Lokal: Zero Data Exfiltration. Keine Transmissionen. Keine Logs (außer du willst es). Offline möglich. DSGVO-konform per Default.
Für Entwickler mit proprietärem Code, für Unternehmen mit Compliance-Anforderungen, für alle, die ihre Daten nicht aus der Hand geben wollen: Lokale KI ist 2026 keine Nerd-Spielerei mehr, sondern die logische Wahl.
So startest du in 10 Minuten
Option A: Ollama (CLI)
# Installation (macOS/Linux)
curl -fsSL https://ollama.com/install.sh | sh
# Modell herunterladen + starten
ollama run llama3.1
# Fertig. Chat läuft.Option B: LM Studio (GUI)
- lmstudio.ai downloaden
- Installieren, öffnen
- Modell suchen (z.B. “Llama 3.1 8B Q4”)
- Download klicken
- Chat starten
Beide Optionen: unter 10 Minuten von Null zu laufender lokaler KI.
Mein Setup
Ollama als Backend (CLI + API), Open WebUI als Chat-Interface, Continue.dev in VSCode für Code-Completion. Llama 3.1 8B für schnelle Tasks, DeepSeek V3 (quantized) für komplexe Sachen.
Kosten nach GPU-Investment: ~40€/Monat Strom. Dafür: unbegrenzte, private, offline-fähige KI.
Ich nutze lokale Modelle auch als Fallback in meinem Paperclip Agent-System — der Night Worker läuft nachts auf Ollama und kostet damit keinen einzigen API-Token.
Hast du schon mal lokale KI ausprobiert? Oder ist Cloud noch bequemer?. TRMT